Universidad de Guadalajara
Centro Universitario de Ciencias Exactas e Ingenierías
Taller de Redes Avanzadas
Luis Angel saldaña Torres
303350797
Spanning Tree Protocol
Spanning Tree Protocol (SmmTPr) es un protocolo de red de nivel 2 de la capa OSI, (nivel de enlace de datos). Está basado en un algoritmo diseñado por Radia Perlman mientras trabajaba para DEC. Hay 2 versiones del STP: la original (DEC STP) y la estandarizada por el IEEE (IEEE 802.1D), que no son compatibles entre sí. En la actualidad, se recomienda utilizar la versión estandarizada por el IEEE.
Su función es la de gestionar la presencia de bucles en topologías de red debido a la existencia de enlaces redundantes (necesarios en muchos casos para garantizar la disponibilidad de las conexiones). El protocolo permite a los dispositivos de interconexión activar o desactivar automáticamente los enlaces de conexión, de forma que se garantice que la topología está libre de bucles. STP es transparente a las estaciones de usuario.
Los bucles infinitos ocurren cuando hay rutas alternativas hacia una misma máquina o segmento de red de destino. Estas rutas alternativas son necesarias para proporcionar redundancia, ofreciendo una mayor fiabilidad. Si existen varios enlaces, en el caso que uno falle, otro enlace puede seguir soportando el tráfico de la red. Los problemas aparecen cuando utilizamos dispositivos de interconexión de nivel de enlace, como un puente de red o un conmutador de paquetes.
Cuando hay bucles en la topología de red, los dispositivos de interconexión de nivel de enlace reenvían indefinidamente las tramas Broadcast y multicast, al no existir ningún campo TTL (Time To Live, Tiempo de Vida) en la Capa 2, tal y como ocurre en la Capa 3. Se consume entonces una gran cantidad de ancho de banda, y en muchos caso la red queda inutilizada. Un router, por el contrario, sí podría evitar este tipo de reenvíos indefinidos. La solución consiste en permitir la existencia de enlaces físicos redundantes, pero creando una topología lógica libre de bucles. STP permite solamente una trayectoria activa a la vez entre dos dispositivos de la red (esto previene los bucles) pero mantiene los caminos redundantes como reserva, para activarlos en caso de que el camino inicial falle.
Si la configuración de STP cambia, o si un segmento en la red redundante llega a ser inalcanzable, el algoritmo reconfigura los enlaces y restablece la conectividad, activando uno de los enlaces de reserva. Si el protocolo falla, es posible que ambas conexiones estén activas simultáneamente, lo que podrían dar lugar a un bucle de tráfico infinito en la LAN.
Existen múltiples variantes del Spaning Tree Protocol, debido principalmente al tiempo que tarda el algoritmo utilizado en converger. Una de estas variantes es el Rapid Spanning Tree Protocol
El árbol de expansión (Spanning tree) permanece vigente hasta que ocurre un cambio en la topología, situación que el protocolo es capaz de detectar de forma automática. El máximo tiempo de duración del árbol de expansión es de cinco minutos. Cuando ocurre uno de estos cambios, el puente raíz actual redefine la topología del árbol de expansión o se elige un nuevo puente raíz.
FuncionamientoEste algoritmo cambia una red física con forma de malla, en la que existen bucles, por una red lógica en árbol en la que no existe ningún bucle. Los puentes se comunican mediante mensajes de configuración llamados Bridge Protocol Data Units (B.P.D.U).
El protocolo establece identificadores por puente y elige el que tiene la prioridad más alta (el número más bajo de prioridad numérica), como el puente raíz. Este puente raíz establecerá el camino de menor coste para todas las redes; cada puerto tiene un parámetro configurable: el Span path cost. Después, entre todos los puentes que conectan un segmento de red, se elige un puente designado, el de menor coste (en el caso que haya mismo coste en dos puentes, se elige el que tenga el menor identificador "direccion MAC"), para transmitir las tramas hacia la raíz. En este puente designado, el puerto que conecta con el segmento, es el puerto designado y el que ofrece un camino de menor coste hacia la raíz, el puerto raíz. Todos los demás puertos y caminos son bloqueados, esto es en un estado ya estacionario de funcionamiento.
Elección del puente raíz
La primera decisión que toman todos los switches de la red es identificar el puente raíz ya que esto afectará al flujo de tráfico. Cuando un switch se enciende, supone que es el switch raíz y envía las BPDU que contienen la dirección MAC de sí mismo tanto en el BID raíz como emisor. Cada switch reemplaza los BID de raíz más alta por BID de raíz más baja en las BPDU que se envían. Todos los switches reciben las BPDU y determinan que el switch que cuyo valor de BID raíz es el más bajo será el puente raíz. El administrador de red puede establecer la prioridad de switch en un valor más pequeño que el del valor por defecto (32768), lo que hace que el BID sea más pequeño. Esto sólo se debe implementar cuando se tiene un conocimiento profundo del flujo de tráfico en la red.
Elección de los puertos raízUna vez elegido el puente raíz hay que calcular el puerto raíz para los otros puentes que no son raíz. Para cada puente se calcula de igual manera, cual de los puertos del puente tiene menor coste al puente raíz, ese será el puerto raíz de ese puente.
Elección de los puertos designados [editar]Una vez elegido el puente raíz y los puertos raíz de los otros puentes pasamos a calcular los puertos designados de cada LAN, que será el que le lleva al menor coste al puente raíz. Si hubiese empate se elige por el ID más bajo.
Puertos bloqueados
Aquellos puertos que no sean elegidos como raíz ni como designados deben bloquearse.
Mantenimiento del Spanning TreeEl cambio en la topología puede ocurrir de dos formas:
El puerto se desactiva o se bloquea
El puerto pasa de estar bloqueado o desactivado a activado
Cuando se detecta un cambio el switch notifica al puente raíz dicho cambio y entonces el puente raíz envía por broadcast dicha cambio. Para ello, se introduce una BPDU especial denominada notificación de cambio en la topología (TCN). Cuando un switch necesita avisar acerca de un cambio en la topología, comienza a enviar TCN en su puerto raíz. La TCN es una BPDU muy simple que no contiene información y se envía durante el intervalo de tiempo de saludo. El switch que recibe la TCN se denomina puente designado y realiza el acuse de recibo mediante el envío inmediato de una BPDU normal con el bit de acuse de recibo de cambio en la topología (TCA). Este intercambio continúa hasta que el puente raíz responde.
Estado de los puertos
Los estado en los que puede estar un puerto son los siguientes:
Bloqueo: En este estado sólo se pueden recibir BPDU's. Las tramas de datos se descartan y no se actualizan las tablas de direcciones MAC (mac-address-table).
Escucha: A este estado se llega desde Bloqueo. En este estado, los switches determinan si existe alguna otra ruta hacia el puente raíz. En el caso que la nueva ruta tenga un coste mayor, se vuelve al estado de Bloqueo. Las tramas de datos se descartan y no se actualizan las tablas ARP. Se procesan las BPDU.
Aprendizaje: A este estado se llega desde Escucha. Las tramas de datos se descartan pero ya se actualizan las tablas de direcciones MAC (aquí es donde se aprenden por primera vez). Se procesan las BPDU.
Envío: A este estado se llega desde Aprendizaje. Las tramas de datos se envían y se actualizan las tablas de direcciones MAC (mac-address-table). Se procesan las BPDU.
Desactivado: A este estado se llega desde cualquier otro. Se produce cuando un administrador deshabilita el puerto o éste falla. No se procesan las BPDU.
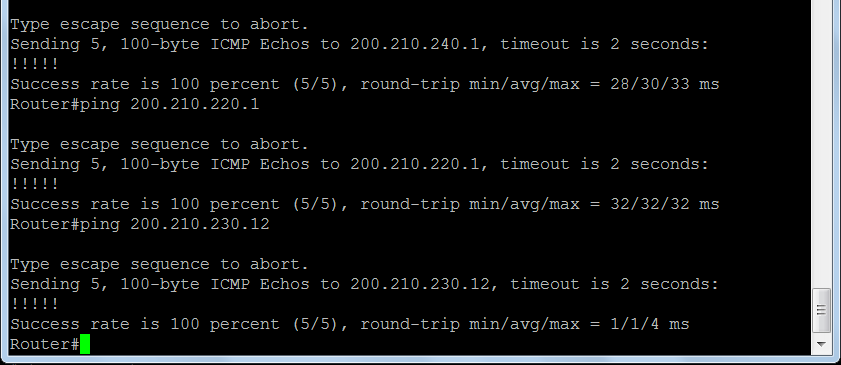
Desarrollo de la prácticaUtilizamos el emulador de terminal "putty" y le asiganamos el numero de puerto serial de la computadora en el cual fue conenctado el cable de consola... en mi caso es el puerto "COM21".

Ingresamos al Switch...(ver pasos previos en las diapositivas del desarrollo de la práctica)


Y obtenemos respuesta....